 Sign In
Sign In 0 Items (
0 Items ( Search
Search







Global extinction due to global warming has been predicted more times than the Labor Party has claimed it can cool the planet with a new tax. But where do these predictions come from? If you thought it was just calculated from the simple, well known relationship between CO2 and solar energy absorption, you would only expect to see about 0.5o C increase from pre-industrial temperatures as a result of CO2 doubling, due to the logarithmic nature of the relationship. [1]
The runaway 3-6o C and higher temperature increase model predictions depend on coupled feedbacks from many other factors, including water vapour (the most important greenhouse gas), albedo (the proportion of energy reflected from the surface – e.g. more/less ice or clouds, more/less reflection) and aerosols, just to mention a few, which theoretically may amplify the small incremental CO2 heating effect.
______________________
“The world has less than a decade to change course to avoid irreversible ecological catastrophe, the UN warned today.” — The Guardian, Nov 28, 2007
“It’s tough to make predictions, especially about the future.” — Yogi Berra
______________________
Because of the complexity of these interrelationships, the only way to make predictions is with climate models. But are they fit for purpose? Before I answer that question, let’s have a look at how they work.
How do Climate Models Work?
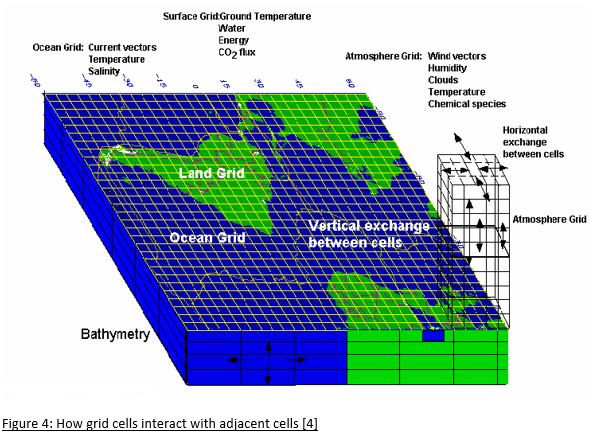
In order to represent the earth in a computer model, a grid of cells is constructed from the bottom of the ocean to the top of the atmosphere. Within each cell, the component properties, such as temperature, pressure, solids, liquids and vapour are uniform.
The size of the cells varies between models and within models. Ideally, they should be as small as possible, as properties vary continuously in the real world, but the resolution is constrained by computing power. Typically, the cell area is around 100×100 km2 even though there is considerable atmospheric variation over such distances, requiring all the cell properties to be averaged. This introduces an unavoidable error into the models even before they start to run.
The number of cells varies between models, but the order of magnitude is around 2 million.

Once the grid has been constructed, the component properties of each these cells must be determined. There aren’t, of course, two million data stations in the atmosphere and ocean. The current number of data points is around 10,000 (ground weather stations, balloons and ocean buoys), plus we’ve had satellite data since 1978, but historically the coverage is poor. As a result, when initialising a climate model starting 150 years ago, there is almost no data available for most of the land surface and oceans, and nothing above the surface or in the ocean depths. This should be understood to be a major concern. [3]

Once initialised, the model goes through a series of timesteps. At each step, for each cell, the properties of the adjacent cells are compared. If one such cell is at a higher pressure, fluid will flow from that cell to the next. If it is at higher temperature, it warms the next cell (whilst cooling itself). This might cause ice to melt, but evaporation has a cooling effect. If ice melts, there is less energy reflected and that causes further heating. Aerosols in the cell can result in heating or cooling and an increase or decrease in precipitation, depending on the type.
Increased precipitation can increase plant growth, as does increased CO2. This will change the albedo (reflectivity) of the surface as well as the humidity. Higher temperatures cause greater evaporation from oceans which cools the oceans and increases cloud cover. Climate models can’t model clouds due to the low resolution of the grid, and whether clouds increase surface temperature or reduce it, depends on the type of cloud.
Of course, this all happens in three dimensions and to every cell, resulting in lots of feedback to be calculated at each timestep.It’s complicated!
The timesteps can be as short as half an hour. Remember, the terminator, the point at which day turns into night, travels across the earth’s surface at about 1700 km/hr at the equator, so even half hourly timesteps introduce further error into the calculation. Again, computing power is a constraint.
While the changes in temperatures and pressures between cells are calculated according to the laws of thermodynamics and fluid mechanics, many other changes aren’t calculated. They rely on parameterisation. For example, the albedo forcing varies from icecaps to Amazon jungle to Sahara desert to oceans to cloud cover and all the reflectivity types in between. These properties are simply assigned and their impacts on other properties are determined from look-up tables, not calculated. Parameterisation is also used for cloud and aerosol impacts on temperature and precipitation. Any important factor that occurs on a subgrid scale, such as storms and ocean eddy currents, must also be parameterised with an averaged impact used for the whole grid cell. Whilst impacts of these factors are based on observations, the parameterisation is far more a qualitative rather than a quantitative process, and often described by modelers themselves as an art, that introduces further error. Direct measurement of these effects and how they are coupled to other factors is extremely difficult.
Within the atmosphere in particular, there can be sharp boundary layers that cause the models to crash. These sharp variations have to be smoothed.
Energy transfers between atmosphere and ocean are also problematic. The most energetic heat transfers occur at subgrid scales that must be averaged over much larger areas.
Cloud formation depends on processes at the millimeter level and are impossible to model. Clouds can both warm as well as cool enough to completely offset the doubled CO2 effect. Any warming increases evaporation (which cools the surface), resulting in an increase in cloud particles. All these effects must be averaged in the models.
When the grid approximations are combined with every timestep, further errors are introduced — and with half-hour timesteps over 150 years, that’s over 2.6 million timesteps! Unfortunately, these errors aren’t self-correcting, instead accumulating over the model run. But there is a technique that climate modelers use in their attempts to overcome this, which I will describe shortly. [4]
Model Initialisation
After the construction of any computer model, there is an initalisation process whereby the model is checked to see whether the starting values in each of the cells are physically consistent with one another. For example, if you are modelling a bridge to see whether the design will withstand high winds and earthquakes, you make sure that before you impose any external forces onto the model structure, that it meets all the expected stresses and strains of a static structure. After all, if the initial conditions of your model are incorrect, how can you rely on it to predict what will happen when external forces are imposed in the model?
Fortunately, for most computer models, the properties of the components are quite well known and the initial condition is static, the only external force being gravity. If your bridge doesn’t stay up on initialisation, there is something seriously wrong with either your model or design!
With climate models, we have two problems with initialisation. Firstly, as previously mentioned, we have very little data for time zero, whenever we chose that to be. Secondly, at time zero, the model is not in a static steady state as is the case for pretty much every other computer model that has been developed. At time zero, there could be a blizzard in Siberia, a typhoon in Japan, a nice day in the UK, monsoons in Mumbai and a heatwave in southern Australia, not to mention the odd volcanic explosion, which could all be gone in a day or so.
There is never a steady state point in time for the climate, so it’s impossible to validate climate models on initialisation.
The best climate modelers can hope for is that their bright and shiny latest model doesn’t crash in the first few timesteps.
The climate system is chaotic which essentially means any model will be a poor predictor of the future – you can’t even make a model of a lottery-ball machine (which is a comparatively a much simpler and smaller interacting system) and use it to predict the outcome of the next draw.
So, if climate models are populated with little more than educated guesses instead of actual observational data at time zero, and errors accumulate with every timestep, how do climate modelers address this problem?
History matching
If the system that’s being computer modelled has been in operation for some time, you can use that data to tune the model and then start the forecast before that period finishes to see how well it matches before making predictions. Unlike other computer modelers, climate modelers call this ‘hindcasting’ because it doesn’t sound like they are fudging the model to fit the data.
Even though climate model construction has many flaws, such as large grid sizes, patchy data of dubious quality in the early years, and poorly understood physical phenomena driving the climate that has been parameterised, the theory is that you can tune the model during hindcasting within parameter uncertainties to overcome all these deficiencies.
But, while it’s true that you can tune the model to get a reasonable match with at least some components of history, the match isn’t unique. When computer models were first being used last century, the famous mathematician, John Von Neumann, said:
with four parameters I can fit an elephant, with five I can make him wiggle his trunk
In climate models there are hundreds of parameters that can be tuned to match history. What this means is there is an almost infinite number of ways to achieve a match. Yes, many of these are non-physical and are discarded, but there is no unique solution as the uncertainty on many of the parameters is large and as long as you tune within the uncertainty limits, innumerable matches can still be found.
An additional flaw in the history-matching process is the length of some of the natural cycles. For example, ocean circulation takes place over hundreds of years, and we don’t even have 100 years of data with which to match it.
So, can the history-matching constrain the accumulating errors that inevitably occur with each model’s timestep?
Forecasting
Consider a shotgun. When the trigger is pulled, the pellets from the cartridge travel down the barrel, but there is also lateral movement of the pellets. The purpose of the shotgun barrel is to dampen the lateral movements and to narrow the spread when the pellets leave the barrel. It’s well known that shotguns have limited accuracy over long distances, that the shot pattern that grows with distance from the muzzle.
The history-match period for a climate model is like the barrel of the shotgun. So what happens when the model moves from matching to forecasting mode?[5]
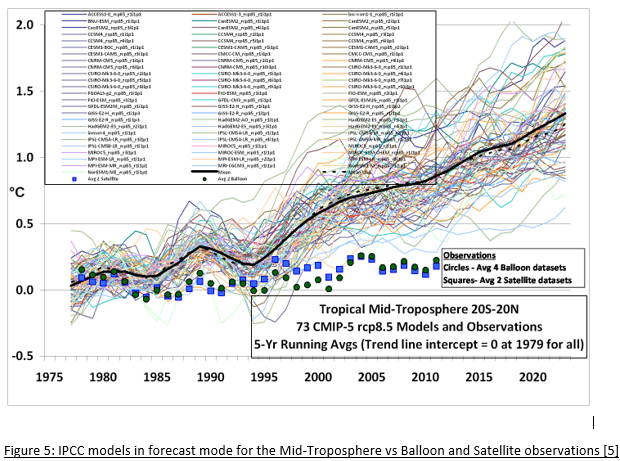
Like the shotgun pellets leaving the barrel, numerical dispersion takes over in the forecasting phase. Each of the 73 models in Figure 5 has been history-matched, but outside the constraints of the matching period, they quickly diverge.
At most only one of these models can be correct, but more likely, none of them are. If this was a real scientific process, the hottest two-thirds of the models would be rejected by the International Panel for Climate Change (IPCC), and further study focused on the models closest to the observations. But they don’t do that for a number of reasons.
Firstly, if they reject most of the models, there would be outrage amongst the climate scientist community, especially from the rejected teams due to their subsequent loss of funding. More importantly, the infamous, much vaunted and entirely spurious ’97 per cent consensus’ would evaporate.
Secondly, once the hottest models were rejected, the forecast for 2100 would be about 1.5o C increase (due predominately to natural warming) and there would be no panic, and the climateers rivers of gold would cease to flow and the gravy train derail. Climate modellers have mortgages too, you know.
So how should the IPPC reconcile this wide range of forecasts?
Imagine that you wanted to know the value of bitcoin 10 years hence so you can make an investment decision today. You could consult an economist, but we all know how useless their predictions are. So instead, you consult an astrologer, but you worry whether you should bet all your money on a single prediction. Just to be safe, you consult 100 astrologers, but they give you a very wide range of predictions. Well, what should you do? You could do what the IPCC does, and just average all the predictions.
Simply put, you can’t improve the accuracy of garbage by averaging it.
An Alternative Approach
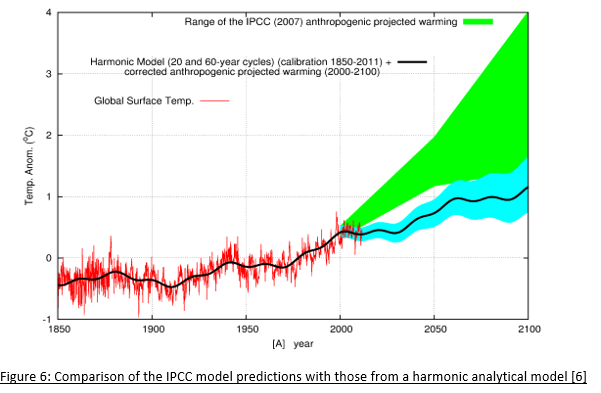
Climate modelers claim that a history-match isn’t possible without including CO2 forcing. This is may be true using the approach described here with its many approximations, and only tuning the model to a single benchmark (surface temperature) while ignoring deviations from others (such as tropospheric temperature), but analytic (as opposed to numeric) models have achieved matches without CO2 forcing. These are models, based purely on historic climate cycles that identify the harmonics using a mathematical technique of signal analysis, which deconstructs long and short term natural cycles of different periods and amplitudes without considering changes in CO2 concentration.
In Figure 6, a comparison is made between the IPCC predictions and a prediction from just one analytic harmonic model that doesn’t depend on CO2 warming. A match to history can be achieved through harmonic analysis and provides a much more conservative prediction that forecasts the current pause in temperature increase, unlike the IPCC models. The purpose of this example isn’t to claim that this model is more accurate — it is, after all, just another model — but to dispel the myth that there is no way history can be explained without anthropogenic CO2 forcing and to show that it’s possible to explain the changes in temperature with natural variation as the predominant driver.[6]
In summary:
♦ Climate models can’t be validated on initiatialisation due to lack of data and a chaotic initial state.
♦ Model resolutions are too low to represent many climate factors.
♦ Many of the forcing factors are parameterised as they can’t be calculated by the models.
♦ Uncertainties in the parameterisation process mean that there is no unique solution to the history matching.
♦ Numerical dispersion beyond the history matching phase results in a large divergence in the models.
♦ The IPCC refuses to discard models that don’t match the observed data in the prediction phase – which is almost all of them.
The question now is, do you have the confidence to invest trillions of dollars and reduce standards of living for millions of people in a bid to stop global warming as predicted by climate modellers? Or should we just adapt to the natural changes as we always have?
Greg Chapman (PhD Physics) is a former (non-climate) computer modeler.
Footnotes
[2] https://serc.carleton.edu/eet/envisioningclimatechange/part_2.html
[3] https://climateaudit.org/2008/02/10/historical-station-distribution/
[4] http://www.atmo.arizona.edu/students/courselinks/fall16/atmo336/lectures/sec6/weather_forecast.html
Whilst climate models are tuned to surface temperatures, they predict a tropospheric hotspot that doesn’t exist. This on its own should invalidate the models.


We should adapt to the changes as we always have.
Congratulations Greg on the best single explanation I have encountered of the nature and operation of the general circulation models on which the dangerous anthropogenic global scare rests. These are the models that are surveyed very 5 years or so by the Coupled Model Intercomparison Project, and then passed forward into the global assessment reports by the IPCC.
You treat the data, parameterisation and computation problems very well, and I would add only two comments, and one query.
(I) the absence of representative ocean temperature records before the age of steamships and even since the introduction of Argos diving buoys is dire. The ocean is much more important than the atmosphere in heat storage and exchange.
(I) you refer in passing to the ‘97% consensus’ myth, but that has nothing to do with the modelling problems. It was simply a (biased) survey of how many papers in all fields mentioned global warming in their abstracts as a rationalisation of why that paper was allegedly relevant. They generally offered no view on how much global warming was anthropogenic, or dangerous.
Finally, a query. I have read somewhere that in parametrising models, the decadal influences of Pacific and Atlantic cycles such as the El Niño/La Niña oscillation are simple ignored, with the cycles assumed implicitly to be permanently neutral. Is that true? If so, that would be a major extra source of unreality in models purporting to generate climate projections for a century hence.
As regards to your question on El Niño/La Niña oscillation, these can’t even be predicted more than a couple of months out even with short term models. As I mention in the article, ocean oscillations can last for centuries and we have far less than a century of data. Like many other climate features, they are just averaged out.
The Southern oscillation is linked to the Sun.
ENSO – vukcevic.co.uk
So unless the Global atmospheric climate models can predict this metric, they will always be wrong.
The Chinese may have some skill in this.
No doubt driven by geopolitical needs, they hacked the Bom when our climate Commissioner was telling us that Australia was doomed to eternal drought.
The play was to purchase the Kidman empire, about 1% of Australia’s continental land mass, with useful property near Woomera Rocket Range.
Since then our agriculture has boomed.
In the meanwhile our own funded BOM has abandoned predicting near term climate change.
A Chinese team has predicted a longer third La Nina, whereas when I last looked a month ago, the conditions were predicted to be neutral by Christmas.
It would be ironic that we may benefit from the BOM hack, by obtaining more accurate climate forecasts from China than our own BOM.
Correction ‘linked to the sun’ should read ‘linked to plate tectonics’
My wife was a geophysical engineer, mathematician, and several allied things to do with this old planet of ours during her working life and apart from rolling about laughing at climate change, something of a Russian joke, she opines that there isn’t enough data to make all these predictions for there are simply too many variables, an example being that most of the dire predictions and the Flanneryisms of these supposed experts have made are so far, are completely wrong! QED
I am no expert but having investigated the subject I decided Modelling was useless and dangerous simply because it cannot factor in all variables and it is mere mortals, with mortgages to pay, deciding what gets left out.
2 million cells? You have to be kidding. I would have thought that it would be around 100 million. That would start to get serious.
Someone described modelling systems as the poorest form of science but that seems to be high praise in light of the Covid and Climate Change fiascos.
One could argue that we would do better examining the entrails of chickens, as they did in ancient times, than putting any faith in Modelling Systems.
Garbage in/Garbage out is the foundation of modelling and dangerously so. It is impossible to factor in all variables for modelling and so mere mortals decide what will be left out, even as they know that including or omitting one variable might change outcomes decisively.
Modelling systems make Astrology look like pure science.
Excellent contribution to the debate. Unfortunately the only places left to contribute to the skeptical side of the debate is on the web not controlled by the censors at Facebook, Google, Linkedin, Twitter, etc. My small contributions can be found at https://adamsmithclub.org/wp-content/uploads/2015/10/AASC-Scientific-Rat-pt1.pdf and https://adamsmithclub.org/wp-content/uploads/2015/10/AASC-ScientificRat-Update.pdf. Let’s hope your article will open some previously closed minds.
rosross: The atmosphere-hydrosphere-lithosphere-biosphere assemblage is the most complex one know about in the entire Universe. It contains niches galore for AGW denialists, contrarians and fossil-carbon shills to find refuge in galore.
3.3 mm/yr = 33 mm/decade = 330 mm/ century = 3,330 mm / millennium
330/100 x 2,500 = 8,250 mm in the last 2,500 years since classical times in Greece.
8,250 mm = 8.25 metres; enough to swamp a fair hunk of the classical world unless compensated for by upward crustal (isostasy) movements.
From which we may conclude that this sea-level rise is comparatively recent in historic time; likely since the Industial Revolution which began C 1750 AD.
http://sealevel.colorado.edu/
If Ian had the slightest idea about what he is talking about rather than spouting the doomsday propaganda of BIG Lithium shills he may realize that there is no such thing as a uniform global sea level and that in many parts around the globe sea level is falling in the contemporary setting. He then might to like to explain, for instance, how Harlech Castle built directly on the coastline of Wales in 1283 now finds itself a mile from the shoreline. Of course, rising sea levels have been a feature over the global environment for the last 12000 years since the transition of the last ice ages of the Pleistocene and the onset of the Holocene (when mean global temperatures increased 4 degrees celsius while atmospheric CO2 decreased), altering coastlines all over the globe in a never-ending dance of ebb and flow. This is a fine example of the natural cyclic harmonics, driven by such things as solar and orbital cycles that the author eludes to in the article and to which Ian and other like-minded BIG Lithium shills remains completely ignorant. Since when were coastlines meant to be eternally static? Just like your own mortality Ian, face it, things change, including the climate and there is nothing you can do about it!
Given the rise and fall of sea levels,i.e. Australia once connected to New Guinea and Tasmania, we can conclude such events are part and parcel of planetary history and have happened before any industrial age, thereby putting to bed the AGW theories. Apart from which, it is no longer called Global Warming because the planet is not warming and the new name is Climate Change which covers all ‘bases’ because the climate is always changing and has always changed.
It’s akin to a doomsday cult formed on the basis of mountain range erosion and formation. Stop Mountain Change Now!
So that data shows that the rate of change has hardly shifted despite the fact that the BRICS are pumping more CO2 into the atmosphere and don’t look like they are going to stop.
To look at it a bit more dispassionately, its best to go home.
https://saltbushclub.com/wp-content/uploads/2019/02/sea-levels-sydney.pdf
Take a look at the CO2 rise and the lack of response by sea level on Pg 9.
There is no parallelism.
The two therefore cannot be related.
The geologists think that the sea level rise is a response to the thaw after the LIA.
We are very lucky that things are thawing out a little during our ice age..
The alternative would be major crop failures and mass starvation.
Thanks Greg, very informative and I’ve passed it on to friends here and in England. You’re pretty generous with the strength of some of your critiques I think ; where you’ve identified a major concern with model data points it seems more like it renders them more or less mere scientific entertainment, that cannot be taken seriously, and the 1700km/hr terminator point making computer power a constraint should be more along the lines of impossible, and also not to be taken seriously,
As Sir James Frazer identified rather despondently a century ago at the end of his life’s work ‘The Golden Bough’ in which he’d set out to prove how pretty well the whole world worked, “The advance of knowledge is an infinite progression towards a goal that ever recedes…….’ and I’d paraphrase that with altering that second last word to ‘forever’.
Yet here we are chasing this impossible chimera and fritting away not millions , not even billions but trillions of dollars…..plus adulterating or destroying many of our hard one improvements in life into the bargain. It really does beggar belief to anyone with even a smidgin of common sense I think, it’s like the world has gone mad…..or else I’m going mad ?
There have been a plethora of predictions over the past three decades from 100 days to save the planet to the rain that falls will not fill our dams. Everyone of those predictions has been wrong and yet politicians and carpetbaggers persist in destroying our economy based on those very predictions. Of course the fundamental prediction upon which all others were based is the original hypothesis which states that as CO2 emissions increase so does temperature. That hypothesis has been proven false many times yet still has a life when it should have been buried 30 years ago. We are not debating sensible scientists or logical politicians but members of the climate change church in which belief is the only requirement for admission. The greatest criminals in this whole charade are the MSM who have not once challenged the stupidity of the believers nor have they ever held the likes of false prophets like Flannery, Gore and Greta to account as their prediction continue to fail. Thankfully there is the alternative press who continue to question the “science” and whose voice is gaining traction. As the reality of high fuel and energy prices strike home more and more ordinary people will demand answers and the politicians who are brave enough to take the right path will be rewarded.